- 浏览: 1212556 次
-

文章分类
最新评论
-
netkongjian:
欢迎加入程序员网址导航[deyi]
准备做一个技术网址导航,请大家分享自己喜欢的技术网站 -
jinshi:
漫画阅读器代码呢?
Android 值得收藏的Demo -
javaboy2010:
非常不错!
老程序员从头开始学JQuery的读书笔记 -
hzfeibao:
很佩服这位仁兄的学习精神和良好的学习习惯,我自己学东西从来都是 ...
老程序员从头开始学JQuery的读书笔记 -
paradigm:
agree
我几年的工作心得,一个菜鸟DBA的心得
IBM HACMP 系列 -- 集群的验证和测试
验证和测试是可靠的配置的精髓,并且是成功实现的基础之一。大多数系统管理员都记得他们的上一个 HACMP 实现,其原因要么是该实现的压力极大,要么是因为一切都按预期顺利进行。
HACMP 集群的优劣由您对其所做的设计、实现和测试工作决定。
尽管 HACMP 是一个功能强大的组件,如果没有正确的测试,在实现后也会成为一场灾难。未经计划的接管、不完善的脚本、莫名中止的节点以及一般的停机时间都可能是未经测试的集群配置的副作用。尽量列出尽可能多的故障场景,创建测试计划,验证所有故障情况下的集群行为,然后仔细检查集群规划,并确保消除了任何单点故障。
务必记住,高可用性不仅包括 HACMP 软件,而且还包括适当的硬件、可靠的软件、具有详细文档记录的设计、高级的自定义、管理和变更管理。
一. 有效性
设计和安装 HACMP 是一回事,让它按您的预期工作完全是另外一回事。只有一种方法可以确定 HACMP 是否按预期工作:测试、检验和验证。务必记住,一旦集群已经运行,生产环境的变更就更难实现(如果可能的话)。
测试和验证可能随所选择的集群解决方案而异;
然而,我们必须一再强调的是,测试可能是整个实现中最重要的组成部分,因为测试做得越多,结果就越好。
尽量模拟能够想象的每种事故;配置的优劣将由您对其所做的测试决定。
我们已不胜其烦地强调了我们认为对于检验和验证配置来说非常重要的一些要点;然而,由于每个配置都是不同的,应该将这些要点用作一般指导原则。
1.1 硬件和许可证先决条件
请考虑以下要点:
(1). 验证您有冗余的电源、排风机、控制器等等。
(2). 验证 sysplanar、适配器、磁盘等的微码级别是最新的。
(3). 验证所使用的每个网络接口与实际交换机端口所报告的速度匹配。
(4). 验证您有足够的软件许可证。有些软件许可证基于处理器 ID 和处理器数量。如果一个节点发生故障,另一个节点应该能够接管。
1.2 操作系统设置
请考虑以下要点:
(1). 验证操作系统,并确保您已安装操作系统或应用程序所需的最新 PTF。
(2). 验证用户数量、每用户允许的最大进程数量、最大文件数量、单个文件的最大大小、堆栈大小等等。
(3). 验证 High Water Mark 和 Low Water Mark。在开始测试时,您可以分别为这两个属性分配值 33 和 24。最佳设置取决于系统配置、应用程序需求、I/O 操作量等等。您将必须监视系统性能一段时间,然后相应地调整这些参数
(4). Syncd frequency.缺省值是 60。应该将其更改为 10,并开始监视集群性能,然后尝试确定能达到满意集群性能的最小值。
(5). 验证您有足够的分页空间。
(6). 验证转存(Dump)设备已正确设置。
(7). 对于频繁使用的文件系统,可能需要单独的 jfslog。确保其名称对所有逻辑卷、文件系统和 jfslog 来说是唯一的。如果对 jfslog 使用系统自动命名,您应该小心。
(8). 验证 /etc/filesystem 中的每个节 (stanza ) 已正确定义。
(9). 验证 /、/var 和 /tmp 中有足够的空间。
(10). 验证 /etc/services 文件。
(11). 确保时钟设置在所有节点上完全相同(日期、时区和 NTP 设置——如果使用的话)。
(12). 如果使用 DNS,请确保正确定义 DNS 服务器,并拥有在 DNS 变得可用时的退回计划。
1.3 集群环境
请考虑以下要点:
(1). 验证 PVID 在所有节点上保持一致。
(2). 验证每个卷组的 quorum 和 auto-varyon 参数已正确设置。
(3). 确保名称对整个集群中的所有逻辑卷、文件系统和 jfslog 来说是唯一的。如果对 jfslog 使用系统自动命名,您应该小心。
(4). 验证所有本地文件系统已装入。
(5). 验证应用程序所有者的 User ID 和 Group ID 在所有节点上完全相同。
(6). 确保应用程序使用的变量和用户配置文件在所有集群节点上保持一致。
(7). 验证 crontab 以及您是否拥有与某个资源组或应用程序相关并且需要与该资源组或应用程序一起进行故障转移的脚本。有关更多信息,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02。
(8). 验证您的应用程序仅由 HACMP 启动。对 /etc/inittab 的检查始终是有用的。
(9). 测试您的应用程序启动/停止和监视脚本(用于自定义监视器),并确保它们能够在无人参与的情况下运行并提供有用的日志记录信息。
(10). 对每个资源组执行手动接管,并记下有关 CPU 和磁盘使用、接管时间等的任何恰当信息。
在自定义应用程序监视和资源组行为时可以进一步使用此信息。
二. 集群启动
在验证系统组件之后,就可以启动集群了。下面几个部分将详细介绍几个有关如何验证启动的示例。
2.1 验证集群服务
在启动集群服务之前,应该验证 clcomd 守护进程已添加到 /etc/inittab 并且已由 init 在集群中的所有节点上启动。
可以使用 SMIT 快速路径 smitty clstart 来启动集群服务。然后,您可以选择希望在其上启动集群服务的节点。可以选择是否希望启动集群锁服务或集群信息守护进程。取决于集群配置,您还可能需要启动集群锁服务(用于并发 RG)。
示例 1 演示了如何启动集群服务。
示例 1 启动集群服务 (smitty clstart)
Start Cluster Services
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* Start now, on system restart or both now +
Start Cluster Services on these nodes [p630n01] +
BROADCAST message at startup? false +
Startup Cluster Lock Services? false +
Startup Cluster Information Daemon? true +
Reacquire resources after forced down ? false +
F1=Help F2=Refresh F3=Cancel F4=List
F5=Reset F6=Command F7=Edit F8=Image
F9=Shell F10=Exit Enter=Do
可以使用命令 lssrc -g cluster 来验证集群服务的状态。取决于集群配置,启动的服务数量可能有所不同;但是,集群管理守护进程 (clstrmgrES)、Cluster SMUX Peer 守护进程 (clsmuxpd) 和集群拓扑服务守护进程 (topsvcsd) 应该在运行。
可以使用诸如 lssrc -g topsvcs 和 lssrc -g emsvcs 等命令来列出不同集群子系统的当前状态。
还可以定义别名来简化验证过程;在我们的场景中,我们使用以下命令创建了一个名为 lsha 的别名:
alias lsha='lssrc -a|egrep "svcs|ES",
然后使用 lsha 来列出所有与集群相关的子系统的状态。
示例 2 演示了如何验证与集群相关的服务的状态。
示例 2 验证集群服务的状态
[p630n02][/]> lssrc -g cluster
Subsystem Group PID Status
clstrmgrES cluster 49830 active
clsmuxpdES cluster 54738 active
clinfoES cluster 45002 active
[p630n02][/]> lssrc -g topsvcs
Subsystem Group PID Status
topsvcs topsvcs 53870 active
[p630n02][/]> lssrc -g emsvcs
Subsystem Group PID Status
emsvcs emsvcs 53638 active
emaixos emsvcs 53042 active
[p630n02][/]> lsha
clcomdES clcomdES 11404 active
topsvcs topsvcs 53870 active
grpsvcs grpsvcs 49074 active
emsvcs emsvcs 53638 active
emaixos emsvcs 53042 active
clstrmgrES cluster 49830 active
clsmuxpdES cluster 54738 active
clinfoES cluster 45002 active
grpglsm grpsvcs inoperative
2.2 IP 验证
要验证 IP 地址,可以执行以下操作:
(1). 使用命令 netstat –in 来验证所有 IP 地址都已配置完毕。
(2). 使用命令 netstat –rn 来验证路由表。
(3). 如果使用 NFS,则使用命令 lssrc -g nfs 来验证 NFS 服务已启动。
2.3 资源验证
要验证资源,可以执行以下操作:
(1). 使用命令 lsvg –o 来验证卷组已启用。
(2). 使用命令 lsvg -l your_volume_group 来验证逻辑卷已打开和同步。
(3). 使用命令 mount 来验证文件系统已装入。
(4). 如果有要导出的文件系统,可以使用命令 showmount –e 来验证它们。
2.4 应用程序验证
要验证应用程序,可以执行以下操作:
(1). 使用命令 ps -ef|grep application_process 来验证应用程序在正常运行。
(2). 验证客户端能够连接。
在 /tmp/hacmp.out log 文件中,查找 node_up 和 node_up_complete 事件。
示例 3 显示了一个示例 node_up 事件。
:node_up[455] exit 0
Jun 30 15:07:19 EVENT COMPLETED:node_up p630n01
HACMP Event Summary
Event:node_up p630n01
Start time:Wed Jun 30 15:07:07 2004
End time:Wed Jun 30 15:07:21 2004
Action:Resource:Script Name:
Acquiring resource group:rg01 process_resources
Search on:Wed.Jun.30.15:07:10.EDT.2004.process_resources.rg01.ref
Acquiring resource:All_service_addrs acquire_service_addr
Search on:Wed.Jun.30.15:07:12.EDT.2004.acquire_service_addr.All_service_addrs.rg01.ref
Resource online:All_nonerror_service_addrs acquire_service_addr
Search on:
Wed.Jun.30.15:07:16.EDT.2004.acquire_service_addr.All_nonerror_service_addrs.rg01.ref
示例 4 显示了一个示例 node_up_complete 事件。
:node_up_complete[314] exit 0
Jun 30 15:07:24 EVENT COMPLETED:node_up_complete p630n01
HACMP Event Summary
Event:node_up_complete p630n01
Start time:Wed Jun 30 15:07:21 2004
End time:Wed Jun 30 15:07:25 2004
Action:Resource:Script Name:
Resource group online:rg01 process_resources
Search on:Wed.Jun.30.15:07:22:00.EDT.2004.process_resources.rg01.ref
如果遇到任何与集群服务启动相关的问题,或者希望全面了解集群启动和所涉及到的进程,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02 中的第 7 章“Starting and Stopping Cluster Services”。
三. 监视集群状态
应该始终监视集群状态,无论是监视集群的整体状态(启动、停止或不稳定),还是监视单独的节点状态(启动、停止、加入、离开或重新配置)。
3.1 使用 clstat
可以使用命令 /usr/sbin/cluster/clstat 来获得有关集群的各个信息片段,包括集群状态、节点数量、节点的名称和状态、资源组的名称和状态,以及接口的名称和状态。要使用此命令,您应该已经启动了 clinfo 守护进程。示例 5 显示了此命令的输出。
示例 5 示例 clstat 输出
clstat - HACMP Cluster Status Monitor
Cluster:bubu (1088583415)
Wed Jun 30 15:21:25 EDT 2004
State:UP Nodes: 6
SubState:STABLE
Node:p630n01 State:UP
Interface:gp01 (0) Address: 10.1.1.1
State:UP
Interface:n01bt1 (1) Address: 172.16.100.31
State:UP
Interface:p630n01 (1) Address: 192.168.100.31
State:UP
Interface:n01a1 (1) Address: 192.168.11.131
State:UP
Resource Group:rg01 State:On line
Node:p630n02 State:UP
Interface:gp02 (0) Address: 10.1.1.2
State:UP
Interface:n01bt2 (1) Address: 172.16.100.32
State:UP
Interface:p630n02 (1) Address: 192.168.100.32
State:UP
Interface:n02a1 (1) Address: 192.168.11.132
State:UP
Resource Group:rg02 State:On line
Node:p630n03 State:UP
Interface:gp03 (0) Address: 10.1.1.3
State:UP
Interface:n01bt3 (1) Address: 172.16.100.33
State:UP
Interface:p630n03 (1) Address: 192.168.100.33
State:UP
*********f/forward, b/back, r/refresh, q/quit ******
如果集群节点具有图形功能,可以使用 /usr/sbin/cluster/clstat 来显示一个描述集群和节点状态的图形窗口。在执行此操作之前,请确保将 DISPLAY 变量导出到 X 服务器地址并允许 X 客户端访问。
该命令的结果应该与图 1 所示的结果类似。
图 1 clstat 的图形显示
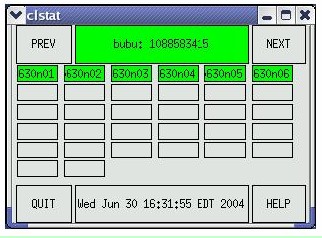
3.2 使用 snmpinfo
如果打算使用基于 SNMP 的监视,务必记住 HACMP 使用 V1 代理。AIX 5L 5.2 缺省使用 V3,因此您必须使用命令 /usr/sbin/snmpv3_ssw -1 来更改版本。
3.3 使用 Tivoli
若要将集群与 Tivoli Monitoring 集成,您需要安装 Tivoli Monitoring 组件。有关操作原理和更多信息,请参阅红皮书 Exploiting HACMP V4.4: Enhancing the Capabilities of Cluster Multi-Processing, SG25979。
四. 集群停止
可以使用 smitty clstop 来停止集群服务。可以选择您希望在其上停止集群服务的所有节点,以及停止类型:graceful、takeover 或 forced。
示例 6 演示了如何停止集群服务。
示例 6 停止集群服务 (smitty clstop)

在一个节点上成功关闭集群服务以后,命令 lssrc -g cluster 的输出应该不包含任何内容。
还可以使用别名命令 lsha 来验证所有与集群相关的进程的状态。
示例 7 演示了如何验证与集群相关的服务的状态。
示例 7 验证集群停止
[p630n01][/]> lssrc -g cluster
Subsystem Group PID Status
[p630n01][/]> lssrc -g topsvcs
Subsystem Group PID Status
topsvcs topsvcs inoperative
[p630n01][/]> lssrc -g emsvcs
Subsystem Group PID Status
emsvcs emsvcs inoperative
emaixos emsvcs inoperative
[p630n01][/]> lsha
clcomdES clcomdES 14896 active
topsvcs topsvcs inoperative
grpsvcs grpsvcs inoperative
grpglsm grpsvcs inoperative
emsvcs emsvcs inoperative
emaixos emsvcs inoperative
请注意,clcomd 守护进程在集群服务停止以后仍在运行。
一个节点上的关闭类型将决定该节点在成功停止集群服务以后获取的资源组将来的行为。
在文件 /tmp/hacmp.out 中,查找 node_down 和 node_down_complete 事件。
示例 8 显示了一个示例 node_down 事件。
示例 8 Node_down 事件
:node_down[306] exit 0
Jun 30 16:14:40 EVENT COMPLETED:node_down p630n01 graceful
HACMP Event Summary
Event:node_down p630n01 graceful
Start time:Wed Jun 30 16:14:28 2004
End time:Wed Jun 30 16:14:43 2004
Action:Resource:Script Name:
Releasing resource group:rg01 process_resources
Search on:Wed.Jun.30.16:14:30.EDT.2004.process_resources.rg01.ref
Releasing resource:All_service_addrs release_service_addr
Search on:Wed.Jun.30.16:14:32.EDT.2004.release_service_addr.All_service_addrs.rg01.ref
Resource offline:All_nonerror_service_addrs release_service_addr
Search on:
Wed.Jun.30.16:14:35.EDT.2004.release_service_addr.All_nonerror_service_addrs.rg01.ref
Resource group offline:rg01 process_resources
Search on:Wed.Jun.30.16:14:37.EDT.2004.process_resources.rg01.ref
示例 9 显示了一个示例 node_down_complete 事件。
示例 9 Node_down_complete 事件
:node_down_complete[352] exit 0
Jun 30 16:14:48 EVENT COMPLETED:node_down_complete p630n01 graceful
HACMP Event Summary
Event:node_down_complete p630n01 graceful
Start time:Wed Jun 30 16:14:43 2004
End time:Wed Jun 30 16:14:48 2004
Action:Resource:Script Name:
Resource group offline:rg01 process_resources
Search on:Wed.Jun.30.16:14:45.EDT.2004.process_resources.rg01.ref
应该尽可能避免使用 kill -9 命令来停止集群管理器守护进程。在这样的情况下,SRC 将检测到 clstrmgr 守护进程异常退出,并将调用 /usr/es/sbin/cluster/utilities/clexit.rc。这样会中止系统,并且可能破坏位于共享存储上的数据。其余节点将根据资源组策略启动接管。
如果遇到任何与集群服务停止相关的问题,或者希望全面了解集群停止进程,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02 中的第 7 章“Starting and Stopping Cluster Services”。
Graceful : 当您指定了此参数时,节点拥有的资源组将被释放,但是不会由其他节点获取。
Graceful with takeover :当您指定了此参数时,该节点拥有的资源组将被释放,并根据资源组类型由其他节点获取。
Forced : 当您指定了此参数时,集群服务将停止,但是资源组不会被释放。
注意:建议不要一次在多个节点上强制关闭集群服务。
若要更好地了解这些选项,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02 中的第 7 章“Starting and Stopping Cluster Services”。
五. 应用程序监视
在启动集群服务以后,请确保应用程序已启动并正在运行,该应用程序提供的所有服务应该可用,并且客户端能够连接。
验证应用程序进程已启动并正在运行,并且该应用程序需要的所有资源(卷组、文件系统、逻辑卷和 IP 地址)都可用。
强烈建议您测试已定义的每个应用程序服务器的启动和停止脚本。取决于运行这些脚本的节点,可能需要对其做出一些修改。必须小心编写启动脚本,以使应用程序能够从任何以前的异常终止中恢复。停止脚本必须使应用程序能够正确关闭,使数据保持同步,并释放所有资源。
5.1 验证应用程序状态
可以使用应用程序进程监视或自定义应用程序监视来监视应用程序的状态。
5.1.1 应用程序进程监视
此类监视使用 RSCT 功能在应用程序进程级别工作,并且非常易于配置。用于监视的值高度依赖于应用程序的特征。建议使用以下指导原则:
(1). 确保已定义了一个应用程序服务器。
(2). 确保使用命令 ps –el 的输出来指定要监视的进程名称。
(3). 确保指定了正确的进程所有者。
(4). 确保指定了正确的实例数量。
(5). 应该选择足够长的稳定间隔,以使应用程序能够从任何以前的异常关闭中恢复。
(6). 确保正确设置了重新启动计数。您不会希望尝试无限期地重新启动某个永远不会在一个节点上启动的应用程序;相反,您应该尝试启动故障转移。
(7). 确保正确设置了重新启动间隔。如果此间隔非常短,则重新启动计数器将会重置,并且故障转移或通知操作可能在应该发生的时候没有发生。
(8). 如果需要在应用程序发生故障的情况下采取任何特殊措施,可以将这些措施包括在在用于清理方法的脚本中。
5.1.2 自定义应用程序监视:
您必须编写自己的脚本来监视与您的应用程序相关的所有参数。应该在无法使用应用程序进程监视的时候使用此方法。如果应用程序工作正常,确保您的脚本返回退出代码 0。
5.2 验证资源组状态
在监视集群时,您可能希望查看资源组和拓扑的状态。资源组可以处于以下状态中的某一种状态:在线、离线、获取、释放、错误、临时错误或未知。
可以使用命令 /usr/es/sbin/cluster/utilities/clfindres 或 clRGinfo 来确定资源组的状态。两种方法的结果应该完全相同,因为 /usr/es/sbin/cluster/utilities/clfindres 调用 clRGinfo。
此命令的最常用标志包括:
-t 如果希望显示某个自定义资源组的停留时间和延迟退回计时器设置,则使用此标志。
-p 如果希望显示某个资源组的优先级覆盖位置 (priority override location),则使用此标志。
有关这些标志的进一步详细信息,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02 中的第 7 章“Starting and Stopping Cluster Services”。
示例 10 显示了此命令在带 –p 标志运行时的输出。

示例 10 示例 clRGinfo -p 输出
始终可以使用命令 /usr/es/sbin/cluster/utilities/cltopinfo 来检查集群拓扑,如示例 11 所示。
示例 11 Cltopinfo 示例输出
Cluster Description of Cluster:bubu
Cluster Security Level:Standard
There are 6 node(s) and 7 network(s) defined
NODE p630n01:
Network net_diskhb_01
Network net_diskhb_02
p630n01_hdisk30_01 /dev/hdisk30
Network net_ether_01
gp01 10.1.1.1
Network net_ether_02
n02a1 192.168.11.132
n04a1 192.168.11.134
n03a1 192.168.11.133
n06a1 192.168.11.136
n05a1 192.168.11.135
n01a1 192.168.11.131
p630n01 192.168.100.31
n01bt1 172.16.100.31
Network net_rs232_01
Network net_rs232_02
Network net_rs232_03
NODE p630n02:
Network net_diskhb_01
可以使用不同的标志来对输出进行格式设置。请参见此命令的手册页面。
有关可用于集群状态监视的工具的详细描述,请参阅 HACMP for AIX 5L V5.1 Adminstration and Troubleshooting Guide, SC23-4862-02 的第 8 章“Monitoring an HACMP Cluster”。
5.3 验证 NFS 功能
注意:在开始使用 NFS 之前,应该注意恢复功能和锁还原功能(在 NFS 服务器故障的情况下)仅对两节点的集群可用。
在使用 HACMP 时,您应该注意,在 NFS 的实现方式方面存在一些限制。如果使用通过 IP 别名或替换的 IPAT,则 NFS 行为会有所不同。请记下您的文件系统属于哪一种资源组类型(级联、循环或自定义),以及可用的服务数量、启动接口和路由表中的路由。
可以在两种不同类型的 NFS 装入之间做出选择:硬挂载和软挂载。
(1). 如果尝试对某个文件系统进行软装入,并且导出 NFS 服务器不可用,您将会接收到一个错误。
(2). 当导出 NFS 服务器不可用时,尝试对某个文件系统进行硬装入的客户端将会一直尝试,直到该服务器变得可用,这种情况可能不适合于您的应用程序。
注意:缺省选择是硬装入。
确保每个节点的主机名称与服务标签匹配是推荐的普遍做法,因为有些应用程序使用主机名称。
在我们测试 NFS 的例子中,我们将使用一个包含两个节点、两个级联资源组和两个通过服务地址导出的文件系统的集群。
我们使用了以下步骤来测试 NFS 功能:
1. 定义两个卷组 vg01 和 vg02。确保每个卷组的主编号在两个节点上完全相同。
2. 在每个卷组中定义一个逻辑卷和一个将导出的文件系统,并将它们命名为 /ap1_fs 和 /app2_fs。确保逻辑卷名称和 jfslog 名称在两个节点上保持一致。
3. 可以使用 C-SPOC 执行前面的任务,并且不应该担心卷组主编号、逻辑卷名称或 jfslog 名称在整个集群中的唯一性。
4. 定义两个级联资源组,名字为:rg01 和 rg02。
5. 对于 rg01,将参与节点定义为 node 1 和 node 2。
6. 对于 rg02,将参与节点定义为 node 2 和 node 1。
7. 创建两个将用于挂载文件系统的目录:
/mount_point1 和 /mount_point2。
8. 运行 smitty hacmp 并转到 Change/Show All Resources and Attributes for a Cascading Resource Group 菜单。
9. 对于 rg01m:
(1). 在 Filesystems 字段中输入 /app1_fs
(2). 在 Filesystem mounted before IP Configured 字段中选择 True
(3). 在 Filesystems/Directories to Export 字段中输入 /app1_fs
(4). 在 Filesystems/Directories to NFS mount 字段中输入 /mount_point1;/app1_fs
(5). 在 Network For NFS Mount 字段中选择服务网络
10. 对于 rg02:
(1). 在 Filesystems 字段中输入 /app2_fs
(2). 在 Filesystem mounted before IP Configured 字段中选择 True
(3). 在 Filesystems/Directories to Export 字段中输入 /app2_fs
(4). 在 Filesystems/Directories to NFS mount 字段中输入 /mount_point2;/app2_fs
(5). 在 Network For NFS Mount 字段中选择服务网络
11. 如果计划使用特定的 NFS 导出选项,则必须编辑文件 /usr/es/sbin/cluster/etc/exports。该文件的格式与 /etc/exports 文件的格式相同。
12. 同步集群资源。
13. 在两个节点上启动集群服务。
14. 通过分别运行命令 lssrc -g cluster 和 lssrc -g nfs 来验证集群和 NFS 服务已成功启动。
15. 验证 vg01 已在 node 1 上启用。/filesystem1 应该已在本地挂载,/filesystem2 应该已经实现 NFS 挂载。使用命令 showmount –e 来验证 node 1 已对 /filesystem1 进行了 NFS 导出。
16. 验证 vg02 已在 node 2 上启用。/filesystem2 应该已在本地挂载,/filesystem1 应该已经实现 NFS 挂载。使用命令 showmount –e 来验证 node 2 已对 /filesystem2 进行了 NFS 导出。
17. 使用 takeover 选项停止 node 1 上的集群服务。
18. 验证 vg01 已在 node 2 上启用。/filesystem1 和 /filesystem2 应该同时实现了本地和 NFS 装入。它们还应该实现了 NFS 导出。
19. 重新启动 node 1 上的集群服务。/filesystem1 应该再次同时实现了本地和 NFS 装入。node 2 应该能够对 /filesystem1 进行 NFS 装入。
六. 节点故障转移时的集群行为
通过在预计要发生故障的节点上关闭电源或者运行命令 cp /dev/zero /dev/kmem 或 halt –q 来模拟节点崩溃。
验证故障节点获取的资源组将按预期的方式迁移,并且集群仍然向其客户端提供服务。
七. 测试 IP 网络
在测试发生 IP 故障时的集群行为之前,您必须确保正确设置将运行集群的网络环境:
(1). 如果网络使用 VLAN,则要确保所有物理接口连接到同一个 VLAN。
(2). 如果集群使用 MAC 地址接管,则要确保交换机端口未绑定到特定的 MAC 地址。
(3). 将接口速度设置为特定的值,并在可能的情况下使用双工通信。确保为接口设置的速度与交换机接口的速度匹配。验证您在故障转移情况下将拥有相同的设置。
(4). 验证与 ARP 相关的网络环境设置。启用代理 ARP 的路由器可能会干扰集群接管。验证您的网络支持免费 ARP 和 UDP 广播。
(5). 应该避免使用活动网络设备(路由器、第 3 层交换机、防火墙等等)来连接到集群节点,因为这些类型的设备可能阻止用于集群节点之间通信的 UDP 广播和其他类型的消息。
(6). 验证任何网络接口的故障不会导致集群分割。
7.1 通信适配器故障
我们添加了一些步骤,以模拟包含不确定数量接口的节点上的网络接口故障:
1. 从该适配器中拔出电缆。
2. 如果该适配器配置了服务 IP 地址,则:
· 在 /tmp/hacmp.out 中验证发生了事件“swap_adapter”。
· 使用命令 netstat –in 验证服务 IP 地址已经转移。
o 如果在使用通过 IP 别名的 IPAT,则服务 IP 地址应该已经化名到其中一个可用的启动接口上。
o 如果在使用通过 IP 替换的 IPAT,则服务 IP 地址应该已经转移到其中一个可用的备用接口。
· 验证持久地址(如有的话)已转移到另一个可用的接口。
· 将电缆插入该网络适配器。
o 如果使用通过别名的 IPAT,则启动 IP 地址应该变得可用。
o 如果使用通过替换的 IPAT,则备用 IP 地址应该可用。
3. 如果该适配器未配置服务 IP 地址,则会从集群中删除其 IP 地址。该接口上配置的任何持久地址应该化名到另一个可用的接口上。
4. 一次一个地拔出和插入所有接口的电缆。
7.2 网络故障
为了避免单点故障,您应该使用多个交换机将集群连接到外部环境,并确保客户端能够使用其中任何一个交换机连接到集群。
可以使用以下步骤来测试集群针对交换机故障的恢复能力:关闭交换机电源,并使用命令 netstat –in 来验证集群 IP 服务地址已迁移(无论是通过别名还是通过替换)到连接到其余交换机的接口。
7.3 验证持久 IP 标签
1. 确保未在任何资源组中定义该持久节点 IP 标签。
2. 使支持该 IP 服务标签的网络接口发生故障。该持久节点 IP 标签应该转移到服务接口所迁移到的同一个启动接口上。
3. 一次一个地使其他网络接口发生故障,并等待集群稳定。
该持久 IP 标签应该迁移到下一个可用的启动接口。
4. 当您使所有的网络接口发生故障时,该 IP 持久标签应该不可用。
5. 重新启用所有网络接口。
6. 停止集群服务。IP 持久标签应该仍然可用。
7. 重新启动该节点。该 IP 持久标签应该仍然可用。
八. 测试非 IP 网络
本部分的目的是描述一些用于测试集群节点之间的非 IP 连接的方法。
8.1 串行网络
可以在集群的任何两个节点之间实现 RS232 心跳检测网络。
要测试两个节点之间的串行连接,可以执行以下步骤:
1. 在两个节点上运行命令 lsdev -Cc tty,以验证预期要使用的 tty 设备可用。下面假设您在串行连接的两端都使用 tty1。
2. 确保将 baud rate 设置为 38400,将 parity 设置为 none,将 bits per character 设置为 8,将 number of stop bits 设置为 1,将 enable login 设置为 disable。
3. 确保使用串口线(null-modem cable)电缆。
4. 确保集群服务未运行。
5. 在 node 1 上,运行命令 cat < /dev/tty1。
6. 在 node 2 上,运行命令 cat /etc/hosts > /dev/tty1。您应该能够在 node 1 的控制台上看到 /etc/hosts。
7. 以相反方向重复此测试。
8.2 SCSI 网络
可以在集群的任何两个节点之间实现 SCSI 心跳检测网络。要测试 SCSI 心跳信号网络,建议执行以下步骤:
1. 验证两个节点上都已安装文件集 devices.scsi.tm.rte。
2. 确保两个节点都正确连接到 SCSI 存储。
3. 确保连接到共享总线的所有设备的 SCSI ID 保持唯一。不要使用编号 7,因为此值在每次配置新添加的适配器或在以服务模式启动系统时由 AIX 分配。
4. 启用每个 SCSI 适配器的目标模式(target mode)。验证 tmscsi 设备处于可用状态。
5. 确保集群服务未运行。
6. 在 node 1 上,运行命令 cat < /dev/tmscsi#.tm,其中 # 是目标设备的 ID。
7. 在 node 2 上,运行命令 cat /etc/hosts > /dev/tmscsi#.in,其中 # 是发起者设备的 ID。您应该能够在 node 1 的控制台上看到 /etc/hosts 文件。
8. 以相反方向重复此测试。
8.3 SSA 网络
可以在集群的任何两个节点之间实现 SSA 心跳检测网络。要测试 SSA 心跳信号网络,建议执行以下步骤:
1. 验证两个节点上都已安装文件集 devices.ssa.tm.rte。
2. 确保使用命令 chdev -l ssar -a node_number=x 来正确设置 SSA 路由器 ID,其中 x 是一个唯一的非零数字。必须使用集群节点的节点 ID 值。
3. 确保两个节点都已正确连接到 SSA 存储。
4. 确保集群服务未运行。
5. 在 node 1 上,运行命令 cat < /dev/tmssa#.tm。
6. 在 node 2 上,运行命令 cat /etc/hosts > /dev/tmssa#.in。您应该能够在 node 1 的控制台上看到 /etc/hosts 文件。
7. 以相反方向重复此测试。
8.4 通过磁盘的心跳信号网络
要测试磁盘心跳信号网络,可以执行以下步骤:
1. 确保磁盘的 PVID 在连接的两个节点上完全相同。
2. 确保同时将磁盘定义为两个集群节点上的某个增强并发卷组的成员。
3. 验证您已安装正确版本的 bos.clvm.enh 和 RSCT 文件集。
4. 运行命令 /usr/es/sbin/cluster/utilities/clrsctinfo -cp cllsif|grep diskhb 并验证节点的同步取得成功。我们使用 hdisk30 来定义集群节点 1 和 2 之间的磁盘检测信号网络,如示例 12 所示。
示例 12 Clrsctinfo 输出示例
|
[p630n02][/]> /usr/es/sbin/cluster/utilities/clrsctinfo -cp cllsif|grep diskhb p630n01_hdisk30_01:service:net_diskhb_02:diskhb:serial:p630n01:/dev/rhdisk30::hdisk30:: p630n02_hdisk30_01:service:net_diskhb_02:diskhb:serial:p630n02:/dev/rhdisk30::hdisk30:: |
5. 在 node 1 上,运行命令 /usr/sbin/rsct/bin/dhb_read –p /dev/hdisk30 –r。您的结果应该与示例 13 所示的结果类似。
示例 13 磁盘检测信号接收
|
[p630n02][/]> /usr/sbin/rsct/bin/dhb_read -p /dev/hdisk30 -r Receive Mode: Waiting for response . . . Link operating normally |
6. 在 node 2 上,运行命令 /usr/sbin/rsct/bin/dhb_read –p /dev/hdisk30 -t。
7. 您的结果应该与示例 14 所示的结果类似。
示例 14 磁盘检测信号传输
|
[p630n01][/]> /usr/sbin/rsct/bin/dhb_read -p /dev/hdisk30 -t Transmit Mode: Detected remote utility in receive mode.Waiting for response . . . Link operating normally |
8. 以相反方向重复此测试。
9. 转到目录 /var/ha/log。
10. 如果集群名为 certification,并且您使用磁盘 27,则运行命令
|
tail -f nim.topsvcs.rhdisk27.certification |
11. 命令的输出应该与示例 15 所示的输出类似。
示例 15 通过磁盘的检测信号的示例日志
|
[p630n02][/]> tail -f /var/ha/log/nim.topsvcs.rhdisk30.certification 06/30 19:24:21.296: Received a SEND MSG command.Dst: . 06/30 19:25:01.798: Received a SEND MSG command.Dst: . 06/30 19:25:42.636: Received a SEND MSG command.Dst: . 06/30 19:26:23.318: Received a SEND MSG command.Dst: . 06/30 19:27:03.836: Received a SEND MSG command.Dst: . 06/30 19:27:44.836: Received a SEND MSG command.Dst: . 06/30 19:28:26.318: Received a SEND MSG command.Dst: . 06/30 19:29:07.376: Received a SEND MSG command.Dst: . 06/30 19:29:48.378: Received a SEND MSG command.Dst: . 06/30 19:30:29.310: Received a SEND MSG command.Dst: . |
九. 发生其他故障时的集群行为
HACMP 处理由集群基础设施(拓扑和组服务)确定的故障,但是还可以对并不直接与 HACMP 组件相关的故障作出反应。
9.1 硬件组件故障
应该验证您在下列场景中仍然能够访问存储在外部磁盘上的数据:
(1). 一个将节点连接到存储的适配器发生故障。
(2). 同一个节点中将该节点连接到存储的多个适配器发生故障。
(3). 一个节点中的一个适配器和另外一个节点中的另一个适配器发生故障。
(4). 电缆故障。
(5). 整个节点发生故障。
(6). 如果使用多个存储机箱,则验证一个机箱的故障。
如果在使用 SSA 技术,应小心检查前面提到的所有场景中的环路连续性和跳线卡 (bypass card) 行为,并验证集群和应用程序仍在正常工作。
如果使用 ESS 或 FAStT 存储,则应该小心验证 LUN 屏蔽和分区。
9.2 Rootvg 镜像和内部磁盘故障
至少使用两个磁盘的镜像 rootvg 可以帮助您避免 rootvg 崩溃。
要测试此场景,建议按照以下步骤操作:
1. 使用命令 lsvg -p rootvg 来验证 rootvg 至少包含两个内部磁盘。
2. 使用命令 lsvg -l rootvg 来验证逻辑卷已同步,并且不存在任何过时分区。
3. 使用命令 bootlist -m normal –o 来验证所有磁盘都已包括在启动列表中。
4. 断开一个磁盘的电源,在热插磁盘的情况下,从磁盘盒中取出磁盘。
5. 验证系统在正常工作。
6. 重新启动系统。
7. 连接断开的磁盘。
8. 同步 rootvg。
9.3 AIX 和 LVM 级别的错误
HACMP 只能检测三种类型的故障:
(1). 网络接口卡故障
(2). 节点故障
(3). 网络故障
集群行为还会受到其它事件的影响,例如卷组定额确失或应用程序故障,但是它不会直接对这些事件作出反应。
9.4 VG 的强制 Varyon
要全面了解此功能,必须充分了解 AIX LVM。
9.4.1 启用定额
当启用了定额时,必须有一半以上的 VGDA 和 VGSA 副本可进行读访问并且内容完全相同,varyonvg 命令才能成功。如果对某个磁盘的写操作发生故障,则会更新其他物理卷上的 VGSA 以指示该故障。只要所有 VGDA 和 VGSA 中有一半以上能够写入,定额就会得以维持,卷组将保持启用。然而,丢失物理卷上的数据将不可用,除非该数据的镜像副本位于另一个可用的物理卷上。
仍然可以使丢失数据的所有副本和该卷组可访问并启用,因为其他磁盘中的大部分 VGDA 和 VGSA 副本仍然可访问。
建议不要在 HACMP 配置中使用定额。
9.4.2 禁用定额
当禁用了定额时,所有的 VGDA 和 VGSA 副本都必须可进行读访问并且内容完全相同,varyonvg 命令才能成功。如果对某个磁盘的写操作发生故障,则会更新其他物理卷上的 VGSA 以指示该故障。只要至少有一个 VGDA 和 VGSA 副本可写,卷组就将保持启用,但是不再保证数据完整性。
9.4.3 强制 Varyon
HACMP V5.1 的这个新功能允许在正常 varyonvg 操作失败的情况下强制执行 varyonvg。
可以通过执行以下步骤来测试强制 Varyon 功能:
1. 定义一个至少包含两个物理卷的卷组。一个卷组应该至少包括一个逻辑卷,该逻辑卷至少应该具有两个位于不同磁盘上的数据副本。至少应该可以从集群的两个节点访问一个卷组。使用 C-SPOC 可以容易地执行此任务。
2. 将前面定义的卷组包括在一个资源组中。该资源组的参与节点应该至少包括两个节点,例如,假设我们定义了一个具有参与节点 node1 和 node2 的级联资源组。
3. 对于该资源,在 Extended Resource Group Configuration 面板中将参数 Use forced varyon of volume groups, if necessary 设置为 True。
4. 同步集群资源。
5. 启动 node 1 和 node 2 上的集群服务。
6. 验证该卷组已在 node 1 上启用。
7. 验证逻辑卷已打开,并且文件系统已装入。
8. 在其中一个文件系统上创建一个测试文件。
9. 使该卷组中足够多的磁盘发生故障,以便仅有一个 VGDA 和 VGSA 副本可用。
10. 在我们的测试中,我们定义了一个包含两个磁盘的卷组,并使用命令 dd if=/dev/zero of=/dev/hdisk5 bs=128 删除了包含两个 VGDA 的磁盘中的 PVID。
此操作将使该磁盘不可用于 Varyon 过程。上述命令的结果如示例 16 所示。
示例 16 从磁盘删除 PVID
|
[p630n02][/]> dd if=/dev/zero of=/dev/hdisk36 bs=128 [p630n02][/]> lquerypv -h /dev/hdisk36 00000000 00000000 00000000 00000000 00000000 |................| 00000010 00000000 00000000 00000000 00000000 |................| 00000020 00000000 00000000 00000000 00000000 |................| 00000030 00000000 00000000 00000000 00000000 |................| 00000040 00000000 00000000 00000000 00000000 |................| 00000050 00000000 00000000 00000000 00000000 |................| 00000060 00000000 00000000 00000000 00000000 |................| 00000070 00000000 00000000 00000000 00000000 |................| 00000080 00000000 00000000 00000000 00000000 |................| 00000090 00000000 00000000 00000000 00000000 |................| |
11. 在 node 1 上,使用 takeover 选项停止集群服务。
12. 验证该卷组已在 node 2 上启用。
13. 验证文件系统已装入,并且可以访问测试文件。
十. RSCT 验证
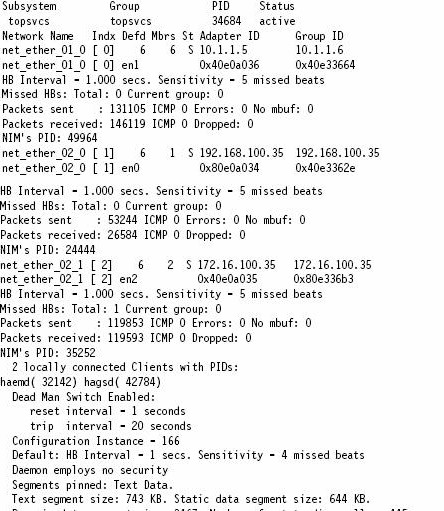
可以使用以下命令进行测试,以确定 RSCT 是否在正常工作:
lssrc -ls topsvcs
此命令的输出如示例 17 所示。
示例 17 lssrc -ls topsvcs 的示例输出
要检查 RSCT 组服务,请参考示例 18。
示例 18 lssrc -ls grpsvcs 的示例输出
|
Subsystem Group PID Status grpsvcs grpsvcs 42784 active 2 locally-connected clients.Their PIDs: 32142(haemd) 21124(clstrmgr) HA Group Services domain information: Domain established by node 2 Number of groups known locally: 3 Number of Number of local Group name providers providers/subscribers ha_em_peers 6 1 0 CLRESMGRD_1088583415 6 1 0 CLSTRMGR_1088583415 6 1 0 |
可以使用 /var/ha/run/topsvcs.your_cluster_name 中的日志文件 cllsif.log 来密切监视通过所有已定义的网络的检测信号。在示例 19 中可以看到该日志文件的一个示例。
示例 19 示例 cllsinfo.log
|
p630n01_hdisk30_01:service:net_diskhb_02:diskhb:serial:p630n01:/dev/rhdisk30::hdisk30:: gp01:boot:net_ether_01:ether:public:p630n01:10.1.1.1::en1::255.255.255.0 p630n01:boot:net_ether_02:ether:public:p630n01:192.168.100.31::en0::255.255.255.0 ... p630n04_tty0_01:service:net_rs232_02:rs232:serial:p630n04:/dev/tty0::tty0:: gp05:boot:net_ether_01:ether:public:p630n05:10.1.1.5::en1::255.255.255.0 |
目录 /var/ha/run/topsvcs.your_cluster_name 中的文件 machines.your_cluster_id.lst 包含有关集群的至关重要的信息。
示例 20 显示了该文件的一个示例。
示例 20 示例 machines.cluster_id.lst
|
*InstanceNumber=166 *configId=1407358441 *!TS_realm=HACMP *!TS_EnableIPAT *!TS_PinText *!TS_PinData *!TS_HACMP_version=6 TS_Frequency=1 TS_Sensitivity=4 TS_FixedPriority=38 TS_LogLength=5000 Network Name net_ether_01_0 Network Type ether *!NIM_pathname=/usr/sbin/rsct/bin/hats_nim *!NIM_Src_Routing=1 *!TS_Frequency=1 *!TS_Sensitivity=5 ... *Node Type Address 2 rhdisk30 255.255.10.1 /dev/rhdisk30 1 rhdisk30 255.255.10.0 /dev/rhdisk30 |
From:
http://www.ibm.com/developerworks/cn/aix/redbooks/HACMP-4/index.html
------------------------------------------------------------------------------
Blog: http://blog.csdn.net/tianlesoftware
网上资源: http://tianlesoftware.download.csdn.net
相关视频:http://blog.csdn.net/tianlesoftware/archive/2009/11/27/4886500.aspx
DBA1 群:62697716(满); DBA2 群:62697977(满)
DBA3 群:62697850 DBA 超级群:63306533;
聊天 群:40132017
--加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请


发表评论

相关推荐
IBM AIX-HACMP-gpfs-Oracle 11g RAC安装部署,很好的文档
详细描述了如何对IBM AIX HACMP集群系统进行配置
IBM hacmp双机C-SPOC操作步骤,例如添加共享磁盘或扩大共享文件系统。
IBM HACMP配置例子,便于配置HACMP
HACMP 概念和实施规划.ppt HACMP IP环境.pdf HACMP log文件.txt HACMP 中四种资源组类型.pdf ... IBM HACMP集群配置.pdf Service ip 2种工作方式.txt 服务 IP 地址.txt 检测验证.txt 策略.txt
IBM HACMP双机服务器系统的解决方案,IBM HACMP双机服务器系统的解决方案
系统软件配置规范-HACMP6.1-V1.3.docx
AIX环境下数据库11G RAC部署向导。 RAC安装使用ASM方式。建立库有独立使用了GPFS集群文件系统技术实现。 同时也解决了只有一个磁盘如何安装RAC的办法--HACMP集群处理磁盘。
大牛之作AIX-HACMP-gpfs-Oracle 11g RAC安装部署
AIX-HACMP-GPFS-Oracle 11g RAC安装部署,这个是小型机上的学习环境安装过程,非常详细!
ibm hacmp oracle 双机集群实施文档
IBM 集群软件HACMP 安装和配置的详细步骤
IBM HACMP听课笔记 IBM HACMP 听课笔记
IBM AIX HACMP培训教程
HX_hacmp6.1_v1.2.docx
某公司的HACMP实际部署案例,可于前面发的EAS部署案例对照
AIX-HACMP-gpfs-11g RAC安装部署
ibm hacmp concepts 6.1